Article · May 20, 2026
From Goldfish to Elephant: How AI Gets Its Memory
A clear look at how tokens, context windows, and model tiers shape what you actually pay.
Although now debunked by scientists, it had been believed for years that a goldfish's memory lasted for no longer than 3 seconds. While we don't know the concrete origins of this myth, let's move forward with it for the purpose of this post. With such a short-term memory, it'd be nearly impossible to engage in a long-term conversation with a goldfish expecting that the fish would be able to recall prior details of the conversation, let alone the conversation's recurring topic. Contrast a goldfish's memory to that of an elephant, an animal believed to never forget. Elephant's brains are among the largest of any land animal and have made use of their capacity for memory to aid in their survival (i.e. recalling water sources, migration patterns, identifying familiar elephants and recalling prior human interactions). While this post isn't a lesson in zoology, the animal lover in me couldn't help but to open my first blog post relating generative AI to animals.
So, what does one have to do with the other? Well, a lot!
Language Models Are Stateless (The Goldfish Problem)
In it's initial state, every API call to a language model starts fresh. The model has no memory between requests which deems the model to be stateless. You can think of it this way: Let's say at a meetup, I introduce myself to a fellow developer. In return, the person enthusiastically introduces themselves and shakes my hand. I follow up with something to the effect of "Nice to meet you!" And to my surprise, the person responds by looking at me weird with no recollection that we've ever met.
That, my friends, is a language model!
They're hopelessly stateless by nature and don't inherently remember any prior interaction in a conversation unless you provide them with sufficient context. End users are given the illusion that their beloved AI agent or assistant remembers everything that it's been told. But the reality is that the app, and not the actual language model itself, is doing all of the work to persist context. For simplicity sake, we'll refer to that context as "memory".
Now of course, developers have found ways to compensate for building with these stateless systems by either passing conversation history back into the user's input, or connecting the language model to systems that help it "remember" things over time.
As a sidebar, I'm still on the fence about the anthromorphisizing of AI. However, I also understand that by assigning AI qualities that align with that of a human is sometimes the most approachable way to digest AI concepts. Therefore, if you ever see me put words in quotes like "remember", just know that it's me being snarky.
Zero Memory - The Stateless Model
I believe that seeing is believing, so let's take a look at a basic API call with one of the Claude models. Assuming that you have access to an Anthropic API key, you can give the code snippet below try. It's created as a loop so that you can have an ongoing conversation with the model via the terminal until you enter quit. Here's what I want you to do:
Start the script and tell the model: My favorite color is green. Then for your next prompt, ask the model: What is my favorite color?
import anthropic
client = anthropic.Anthropic()
while True:
user_message = {
"role": "user",
"content": input("User: ")
}
if user_message["content"] == "quit":
break
message = client.messages.create(
model="claude-haiku-4-5",
max_tokens=1000,
messages=[user_message],
)
response = message.content[0].text
print(response)Get the Sample: github.com/prettywiredbuilds/stateless-agent
Can you believe that the model didn't care enough to remember my favorite color? OK, maybe that's a bit dramatic but I wanted to demonstrate the stateless nature of language models. As the code is written, there's no logic in place for your prior conversation history to persist across each turn of the conversation with the model.
But alas, there are solutions!
Naive Memory — The History List
At it's simplest, you could append each message to a list and pass the full list back to the user's prompt.
It would look something like this:
import anthropic
client = anthropic.Anthropic()
history = []
while True:
user_message = {
"role": "user",
"content": input("User: ")
}
if user_message["content"] == "quit":
break
history.append(user_message)
message = client.messages.create(
model="claude-opus-4-7",
max_tokens=1000,
messages=history
)
response = message.content[0].text
history.append({"role": "assistant", "content": response})
print(response)
print(f'History: {history}')Get the Sample: github.com/prettywiredbuilds/naive-memory
At first glance, it may seem that we've resolved the memory problem. But in reality, we've only scratched the surface of handling the entire ordeal efficiently. There's just one major issue that's preventing the sample above from being an optimal solution: the context window.
Finite Memory: The Context Window
Like a human's brain, language models only have the capacity to take on a finite amount of information before output quality degrades. And once the model reaches it's limit, it taps out.
The context window identifies how many input tokens a language model can handle before it's unable to process and generate more output. The context window varies by language model and is something part of the model's name itself (ex: GPT-4-128k). Some language models have context windows that exceed 1M tokens (ex: Gemini 1.5 Pro). But as you can imagine, those models are more expensive to use in comparison to their smaller context window counterparts.
While storing prior messages in a list may be fine for short conversations, you'll likely run into trouble if you're having a long conversation. In the code sample above, not only are we appending the prior user prompts to the history list, but we're also
appending each of the model's responses. Without a severly limited max_tokens value, the model's response output could be substantially long. As a result, the token count for all of the messages in the
history list could easily max out the limit of the context window.
So one may think: Well, why not use a model with a larger context window?
Don't be fooled by what appears to be a huge upgrade in capacity. While models with larger context windows can support more context/longer prompts, the simple rule of "just because you can doesn't mean that you should" comes into play. As your start to inch closer towards the limit of the context window, the quality of the model's output starts to degrade. It's quite literally like a human brain! If your manager verbally gives you instructions for a 20-part process, you'll likely recall some of what is said but by no means would you remember all details verbatim. You could likely summarize the general gist of what needs to happen, but you'd likely fail to recall each step as it was originally presented to you.
And the there's the persistence issue. Let's say you quit the conversation with the sample above and came back 2 hours later to chat with the model once more. As written, the history of your conversation with the model only persists within it's current session. Once the session
is closed, the conversations saved to the history list cease to exist. While that may be OK for one-off conversations that don't require persisting memory across sessions, it provides a poor user experience if the intended purpose of the assistant is to engage in conversations
with the same user across sessions.
So while the sample provided may work for simple implementations of an AI assistant with "memory", it fails to meet the needs of handling longer conversations with persistent memory across sessions.
But when there's a will, there's a way!
Bounded-Memory — Enter Azure DocumentDB
So essentially, we need to store the conversation history somewhere. A simple history list can hold conversation state in memory, but it is limited to a single process and grows without bound. Storing the conversation in a database gives us persistence across restarts, room to support multiple users and sessions, and a durable full transcript. On top of that storage layer, the application can implement a bounded-memory approach by sending only a rolling summary plus a small recent-message window to the model on each turn.
What's great is that you have your pick in databases! However, your choice in database determines the complexity in implementation.
My preference as of late has been exploring this approach with Azure DocumentDB. For context, Azure DocumentDB provides:
- Persistence across sessions — unlike an in-memory list, conversation history survives restarts and can be retrieved when a user returns days later.
- Native JSON document model — the flexible JSON model with automatic indexing makes it a natural fit for storing message objects (role, content, timestamp) with no rigid schema to maintain.
- Scale without friction — automatic and instant scalability with single-digit millisecond response times means your memory layer won't become a bottleneck as users and conversations grow.
- Multi-user, multi-session support — partition by user ID or session ID to cleanly isolate and query conversation threads at scale.
- A natural path to vector/semantic memory — storing conversation history, semantic embeddings, and agent state in Azure DocumentDB with vector search enables retrieval-augmented generation, making it easy to evolve your memory implementation beyond simple history retrieval.
I created a bounded-memory implemenation for Scout, an AI-powered LA local guide. The assistant ("Scout") keeps a long-running conversation across runs by storing messages in MongoDB, trimming the active history to a fixed token budget, and folding the dropped messages into a rolling summary that is re-injected into the system prompt on every turn.
Get the Sample: github.com/prettywiredbuilds/bounded-memory
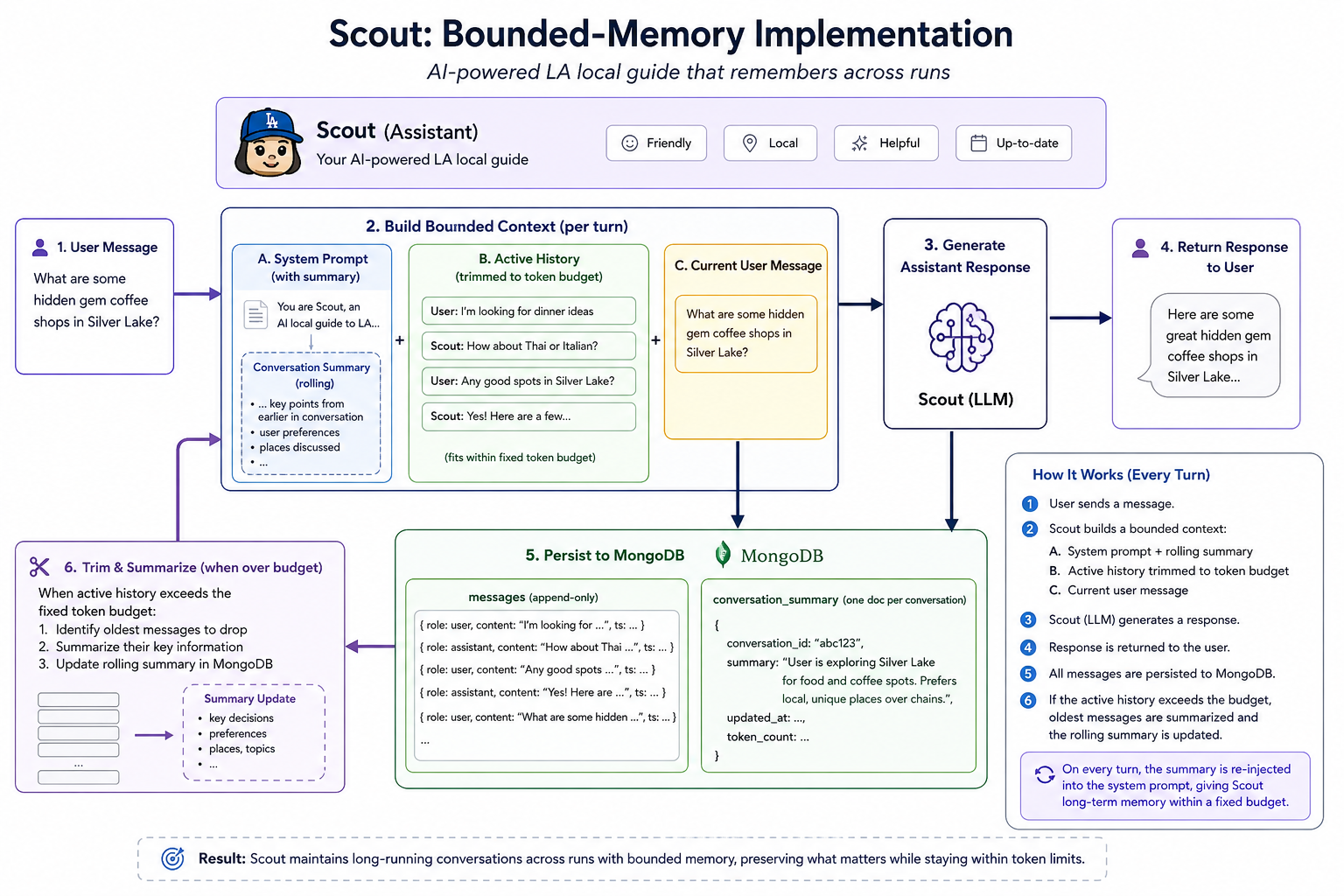
Here's a breakdown of how Scout's setup and how Scout persists it's memory across turns and sessions:
Session resumption is a two-file contract
When the session starts, load_session_id reads .session_id from disk. main.py then queries sessions for that id. If the row exists, the working window and summary come back with it; if not, a fresh document is created. Deleting .session_id starts a new conversation without touching MongoDB. Dropping the sessions row but keeping .session_id will start a fresh conversation under the same id.
The rolling summary lives in the system prompt, not the message list
Once the session is loaded, the app builds the request-time system prompt from the base prompt plus the stored summary. build_request_system_prompt (in utils.py) concatenates the static persona with "Conversation summary so far: …". The summary is not injected as a user message. This keeps the message list a faithful record of real turns, and keeps summary tokens billed as system tokens.
Token counts are model-counted, not estimated
Before sending the user turn, the app computes token counts against the actual request context. get_token_count calls Anthropic's messages.count_tokens endpoint and stores the result on each message at insert time. The trim loop then sums token_count across messages. The cost of this extra round trip is a deliberate trade as it makes the budget enforcement exact rather than approximate (len(text) / 4 style estimates drift badly on code, JSON, and non-English text).
Trimming is exchange-aware, not message-aware
After the assistant responds and both new messages are appended, the app trims the working window to the token budget. get_trimmed_messages_and_dropped_messages (in utils.py) treats the history as a list of user/assistant pairs, not individual messages. It:
- Always keeps the most recent exchange, even if it alone exceeds the budget.
- Walks remaining exchanges newest-first and keeps each whole exchange while the running total stays under
MAX_SESSION_MESSAGE_TOKENS. - Returns the kept window and the dropped prefix as two lists.
This matters because Anthropic's API requires alternating user/assistant roles. Dropping a single message could leave two consecutive user turns at the front and break the next request.
Summarization is incremental, not from-scratch
If trimming dropped older messages, only then does the app merge those dropped turns into the existing summary. merge_summary (in utils.py) sends the existing summary plus only the newly dropped messages to a cheaper model (claude-haiku-4-5, capped at SUMMARY_MAX_TOKENS = 1000). It never re-summarizes the whole transcript. Cost of summary maintenance is therefore bounded per turn and does not grow with conversation length.
The summarizer's system prompt explicitly asks for plain prose and forbids bullets, JSON, or headings. That keeps the summary token-cheap and avoids the model later confusing summary structure with real tool output or instructions.
Two collections, two purposes
The bounded session state is upserted into the sessions collection, and the raw user/assistant messages are appended to the logs collection.
sessionsis read-write, one-doc-per-session. It is what the model reads at the top of every turn. Keeping it small (working window + short summary) is what keeps reads fast and writes cheap.logsis append-only, one-doc-per-message. It is the durable record. If you ever need to rebuild a richer summary, audit the assistant, or replay a session, this is your source.
Together, these two collections give Scout both efficiency and durability. Scout has a lean working memory for the model and a complete archive for everything else.
The Cost of Remembering
Now that we've explored two approaches for giving a model memory, let's dive into each approach's impact on cost.
Naive Full-History
The naive approach resends the entire conversation on every turn. Because language model input is billed per token and the history grows on every turn, the cost of turn N is roughly proportional to N, and the total cost of a conversation of length N is proportional to N². A 100-turn conversation pays for the first turn 100 times.
Bounded-Memory
In contrast, my implemenation with Azure DocumentDB bounds the per-turn input at roughly:
tokens(system_prompt) + tokens(summary) + tokens(working_window ≤ MAX_SESSION_MESSAGE_TOKENS)
ThE Azure DocumentDB approach is cheaper because the amount of conversation context sent to the model on each turn stays capped. Each request includes the system prompt, a short running summary of older context, and a small window of the most recent messages. Even as the conversation gets longer, those pieces stay within fixed limits, so the cost of any single turn stays about the same.
The Verdict
The Bounded-Memory approach is significantly cheaper! The total cost grows steadily with the number of turns, rather than accelerating as the conversation gets longer. If you have twice as many turns, you pay about twice as much overall.
For the Naive Full-History approach, early turns are cheap, but each new turn gets more expensive because it includes everything that came before it. Over a long conversation, that means costs rise faster and faster, because you keep paying again for the same old messages.
Limitations of the Bounded-Memory Sample
I'd be remiss if I didn't call out some of limitations for the Bounded-Memory (i.e. Scout) sample. If you to fork Scout's repo and repurpose for your own needs, consider the following:
- Summarization is lossy - Specific quotes, numbers, or step-by-step reasoning in dropped turns may not survive the merge. While this is fine for a travel guide, it's definitely risky for legal or medical agents.
- Single-user demo - This sample was intentionally created as a single-user demo. There is no auth, no user id, and no multi-session-per-user model. If you're repurposing this sample for your own needs, consider modifying to accommodate the scope of your app/agent.
- No tool calls / no structured content - The trim and summary code assumes plain text
content. Tool-use blocks would need extra handling. - No concurrency control - This sample has two processes pointing at the same
.session_id, which race on the upsert. While this if fine for a single interactive terminal, I'd recommend evolving this approach for a deployed service. - No validation in place for the summary - There is no validator that the merged summary preserves the important facts. A production version would diff-check or score the summary against the dropped messages.
From Goldfish to Elephant
What started as a goldfish, a stateless model with no recollection of anything you've said, can be shaped into something closer to an elephant with the right engineering in place. We went from zero memory, to a naive in-memory list, to a bounded, persistent implementation backed by Azure DocumentDB. Each step solved a real problem: the list gave us continuity within a session; the database gave us persistence across sessions; and the rolling summary kept costs from spiraling as conversations grew. "Memory" in AI is never a given. It's a deliberate engineering choice that developers are responsible for makin since the model doesn't remember anything on its own. We get to decide what gets stored, what gets trimmed, and what gets carried forward. If you want to explore Scout's full implementation and see how all of these pieces fit together in practice, check out the repo: github.com/bounded-memory.