Article · May 25, 2026
Your Prompt Isn't Traveling Alone
When you send a message to a language model, it rarely travels alone. System instructions, conversation history, tool definitions, and retrieved content all hitch a ride, quietly inflating your token count and cost.
Most people assume chatting with a language model looks like this:
I typed a paragraph. The model reads my paragraph.
However, by the time your message reaches the model, it often arrives carrying instructions, prior conversation history, tool definitions, and additional context you may never even see!
But here's the kicker: everything that your prompt brings along with it impacts the cost of consuming language models. Language model consumption is based on the amount of both input tokens and output tokens. Input tokens account for everything sent to the model, while output tokens account for everything the model sends back.
First, a Quick Detour: What Exactly is a Token?
A token is a chunk of text. A common misconception is that tokens = words. However, tokens can be a full word, a part of a word, punctuation or even space. Language models process tokens rather than raw text.
| Text | Possible Tokens |
|---|---|
| hello | 1 token |
| extraordinary | ~3 tokens |
| 👋🏾 | potentially multiple tokens |
Watch the Video: What is a Token?
Before a Model Sees Text, a Tokenizer Gets Involved
So what determines the split of text (or emojis) into tokens? A tokenizer! Tokenizers convert text into tokens. The tokenizer used varies by language model provider. But in any case, here's a conceptual flow of what happens when you submit a prompt to a language model:
- Your Prompt
"Explain tokenization simply"- Tokenizer: Breaks text into chunks/tokens:
["Explain", " token", "ization", " simply"]- Token IDs: Converts tokens into numbers
[12453, 2938, 8120, 992]- Context Window: Packages everything the model receives
[
system instructions,
previous chat history,
retrieved documents,
tool outputs,
your token IDs
]- Model: Processes the token sequence and predicts the next token IDs
[4521, 883, 12734]- Predicted Token IDs: The model outputs numbers, not text
[4521, 883, 12734]- Detokenizer: Converts token IDs back into readable text
["Token", "ization", " is", "..."]- Response Text
"Tokenization is the process of..."Not Every Provider Tokenizes Text the Same Way
Token count is model-dependent. For this post, we'll keep things simple and focus on how OpenAI and Anthropic does tokenization.
OpenAI uses tiktoken, an open-source library created by well, OpenAI . The token encodings tiktoken implements are primarily for OpenAI models, however, you're welcome to use tiktoken outside of the OpenAI ecosystem.
Anthropic uses their own proprietary tokenizer which doesn't have much publicly available information. However, their tokenizer is trained specifically for Claude’s data, so the same sentence can produce a different token count than GPT models.
So in essence, identical text can produce different token counts depending on the provider. Therefore, token estimates aren't universally portable.
The Prompt you Type is Only Part of the Bill
Just above, you likely noticed that the context window also gets tokenized and is included in what the model receives. The content of the context window is the aforementioned baggage that your prompt carries along with it when your prompt is sent to the model. Here's a breakdown of what you'll typically find included:
System instructions
System instructions, sometimes referred to as a system prompt, defines the model behavior. Those instructions include details with regard to the model's personality, rules, formatting constraints, and safety guardrails.
Conversation history
Models are stateless, meaning they don't inherently remember any prior interaction in a conversation unless you provide them with sufficient context. There's various approaches to achieve this and I discuss a few in From Goldfish to Elephant: How AI Gets Its Memory. Approaches aside, conversation pairs or a summary of the prior conversation is typically what gets sent to the model.
Tool definitions
Tools give models a way to interact with the outside world. The model can reason and decide what should happen, but tools let it actually do things. The tool definition itself is a description of available tools, the inputs the tools accept, and when to use them.
On the surface, tool definitions may seem harmless. And honestly, it depends on how many tools an agent has access to use. For example, if an agent has 20 tools, that means that the model is also possibly receiving 20 large JSON schemas, 20 long descriptions, and N examples of each tool. Going from a few tools to a lot of tools will start to add up.
Retrieved content
Retrieved content gives the model information it didn't originally know or wasn't trained on. Instead of relying only on what it remembers, the model gets relevant information pulled in at the moment it needs it. Retrieval usually happens before the full request is sent to the model. There are exceptions with tool-using agents where the model can decide to use a tool and then call a retrieval tool mid-conversation. But classic retrieval augmented generation (RAG) is generally retrieve first then send to model second.
Formatting instructions
Generated text often becomes input for something else. A schema helps ensure the response arrives in the structure other tools, systems, or interfaces are expecting.
When you take the system prompt's tokens and couple it with the tokens from everything above, the cost of what the model receives as input increases significantly.
I Tried Comparing Providers
To help you (and me!) wrap your head around input token costs, I created a Prompt Cost Simulator that can help you understand how input token cost changes based on what gets sent to a language model. It compares two selected models side-by-side and estimates input cost only. I've limited it's functionaloity to support OpenAI (local counting via tiktoken) and Anthropic (official messages.count_tokens endpoint).
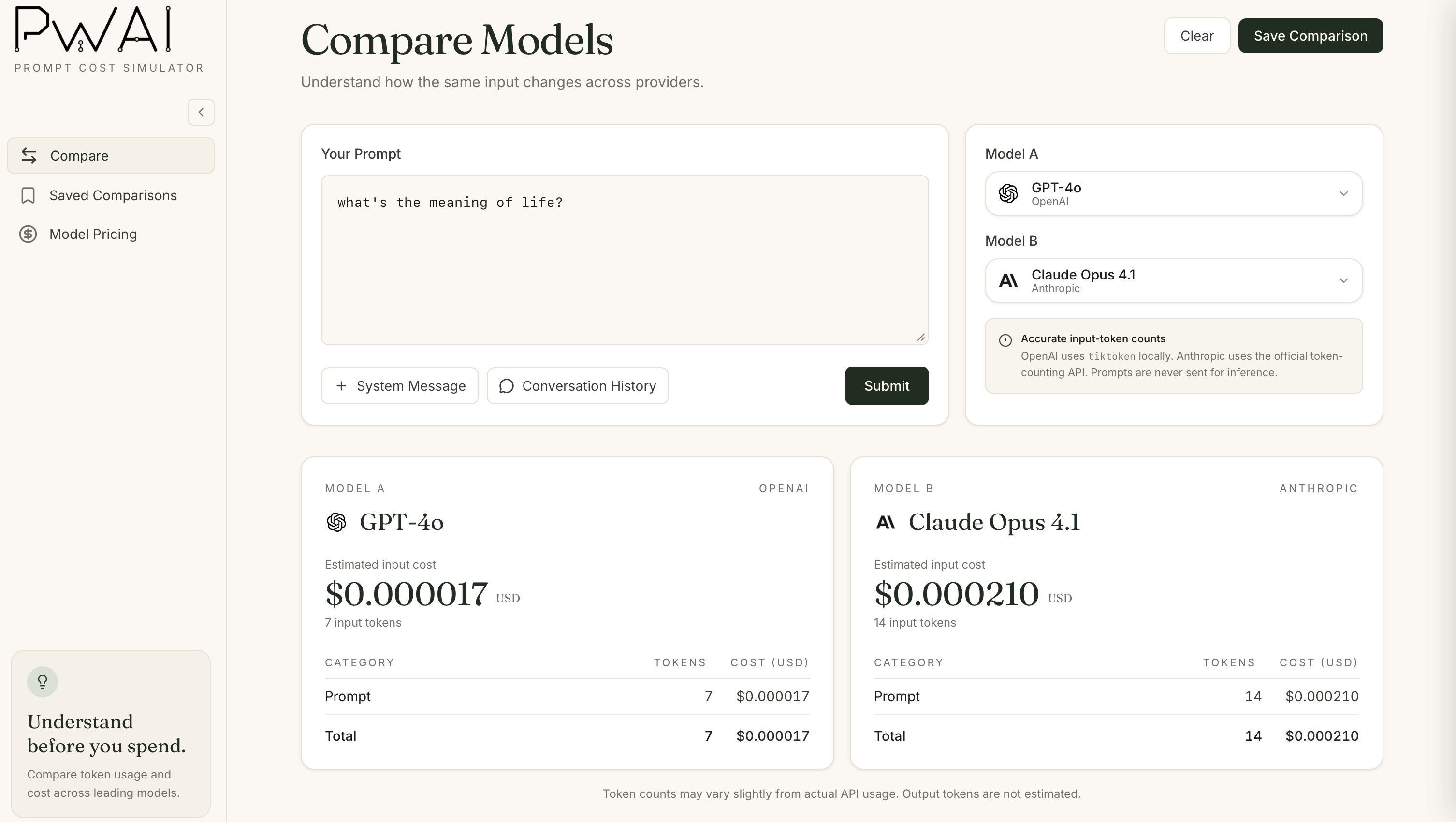
Get the Sample: Prompt Cost Simulator
The app only runs locally and doesn't make inference or completion calls. However, you'll need an Anthropic API key to leverage Anthropic's messages.count_tokens endpoint.
After running a few examples through the simulator, one thing became clear pretty quickly: tokenizers can split the exact same input very differently. The wording never changed, but the token counts did and so did the estimated cost. It was a reminder that cost isn't just tied to what you write, but also how a model interprets it under the hood.
At the same time, model selection isn't always a straightforward "pick the cheapest option" decision. Lower cost doesn't automatically make a model the right fit. Output quality, reasoning ability, latency, and the experience you want your app to deliver all matter, too. Sometimes paying more per token is worth it if the results are meaningfully better.
You're Paying for More Than Your Prompt
We often think we're paying for the message we typed. In reality, we're paying for everything riding along with it: system instructions, chat history, tool definitions, formatting rules, retrieved content, and more. Once you start seeing all of that invisible context, AI pricing starts making a lot more sense!